POS & Payments Platform
Be the best in your business
Lightspeed is the unified point of sale and payments platform powering the world's best businesses at ~168,000 locations worldwide.*
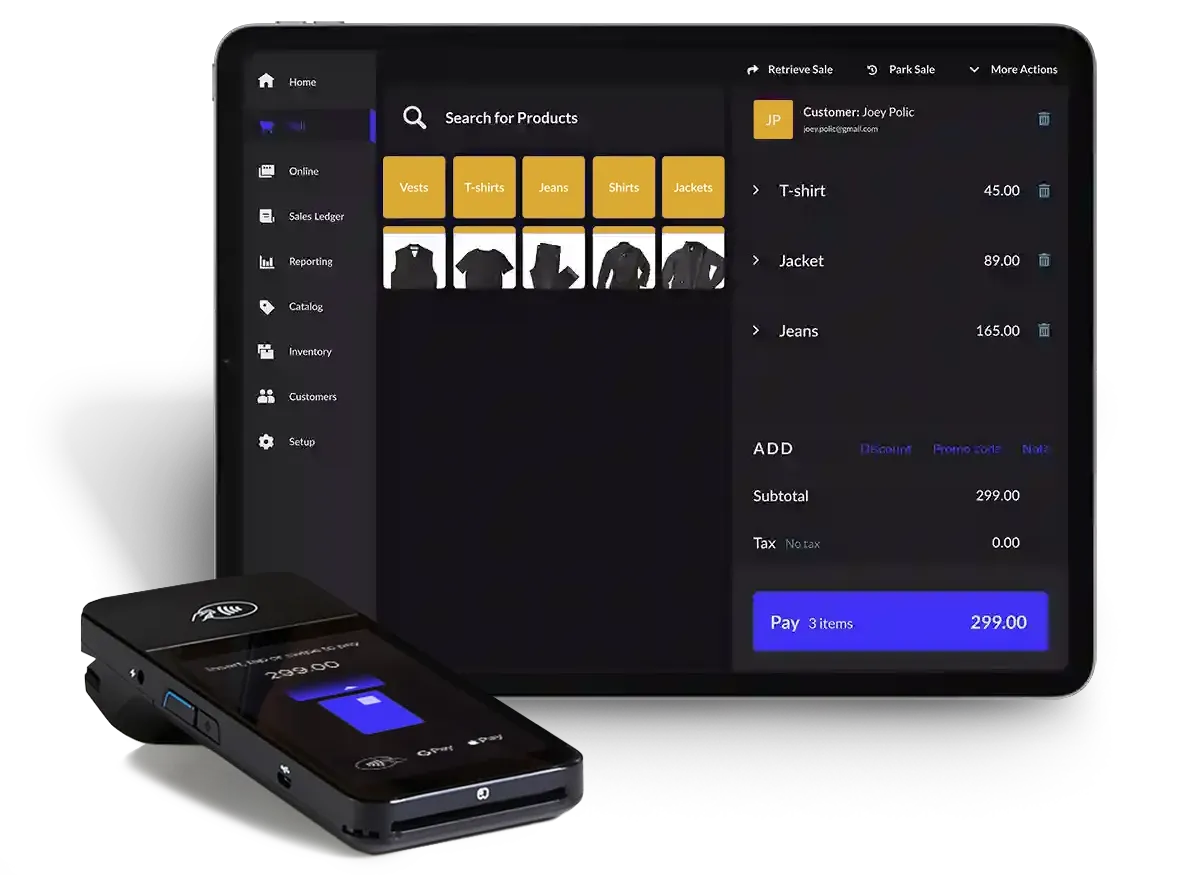
Retail
Become the go-to store.
Grow your revenue, keep staff happy and provide a seamless multichannel experience.

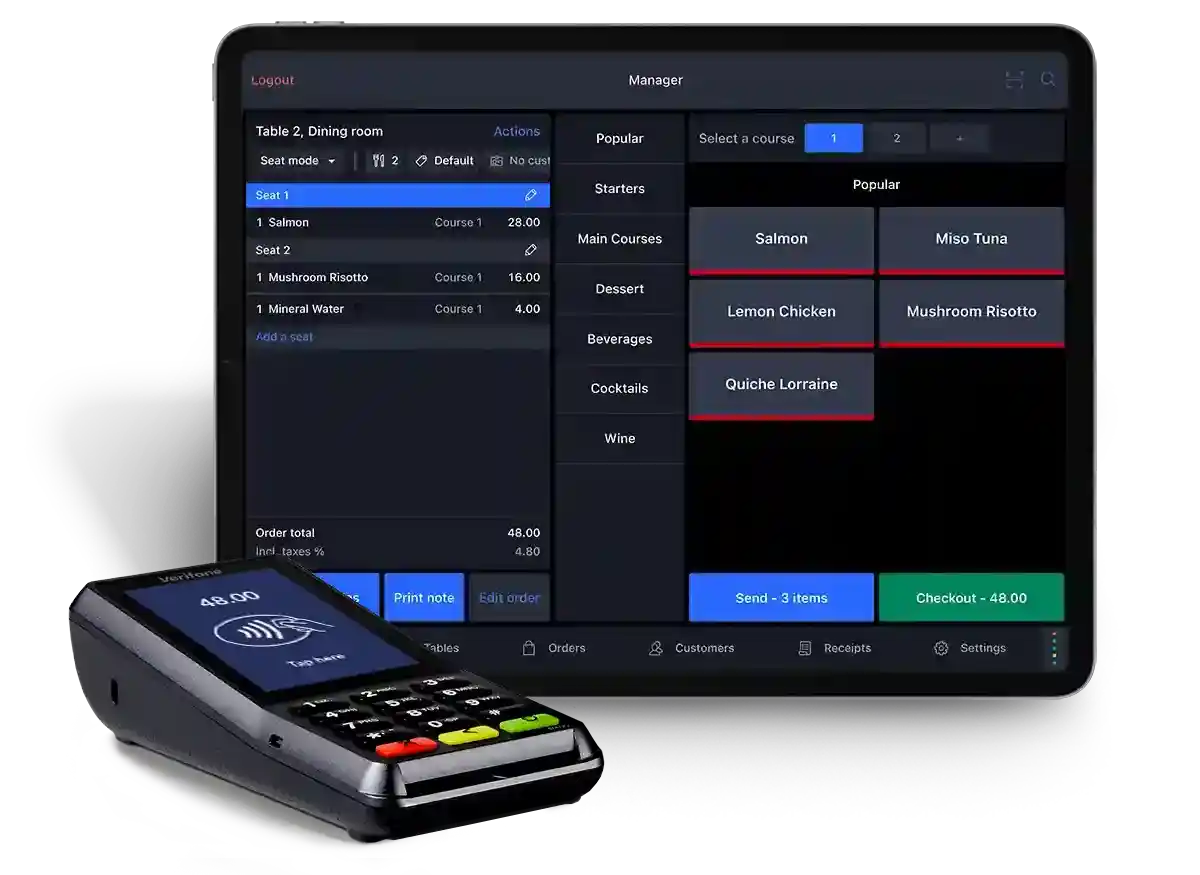
Restaurant
Serve without downtime.
Flip tables faster, increase revenue and offer an exceptional guest experience.

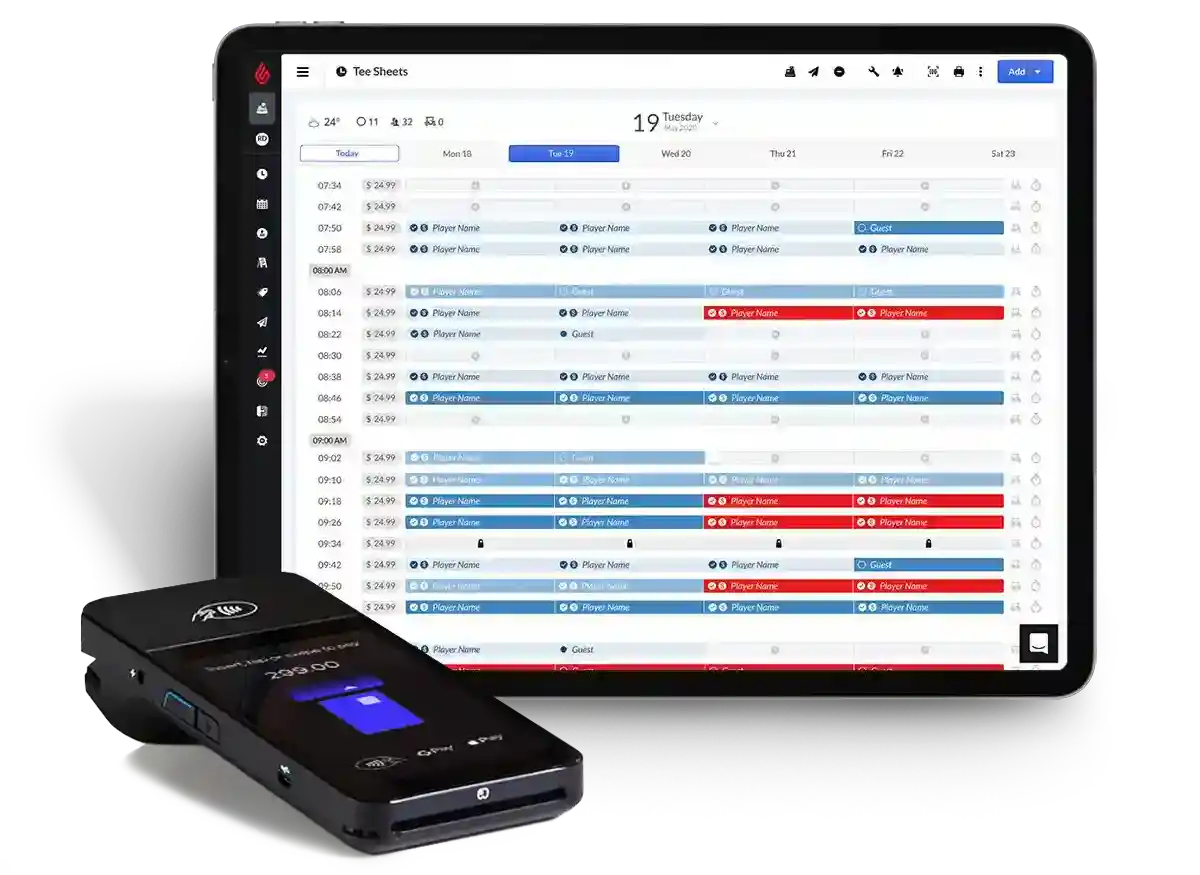
Golf
Manage like a pro.
Run your entire golf business better, from tee sheet to pro shop to F&B operations.

defaultTitle
The commerce platform for ambitious businesses.
From blazing fast workflows to a full suite of integrations, Lightspeed gives you one touchpoint for all your business needs.
- Multichannel and multilocation
- Inventory management
- Fully integrated payments
- Real-time reporting and insights

Your partner in success.
With personalized 24/7 support and solutions that scale with your business, Lightspeed is not just a platform—we’re a partner. Find out why we're trusted by retail and hospitality businesses in over 100 countries.
-
Customer locations as of March 31, 2023. Excluding the impact of Ecwid.